My Homelab Journey


In the event of a COVID-19 outbreak, I am assigned from my company to do work from home. That's when I found out and searching for a new Hobby to do. At that time, seems like tech was still really booming and I found something interesting about having my own server for my need at home. I think it's cool to think like I have "datacenter" on my home. That's when I decided to try homelab.
Starting out with Raspberry Pi 4
At that time, I was thinking to starting slow by using Raspberry Pi. When I search the internet, there was some people that can do cool stuffs using Raspberry Pi. My go-to reference at that time is https://pimylifeup.com/. So I ordered one myself, a Raspberry Pi 4 with 4GB RAM with the top active cooling heatsink and Type C power brick for Rp 1.389.000 or $96.64 (approximately) at that time. I was lucky to buy it before the Pi shortage after COVID few months later.

Despite the size, there was many thing that I do in that tiny little thing. The first time I got that small computer, I was excited to use it as a NAS (Network Attached Storage). I have so many Hard Drives that is laying around in my House. Me and my late father also like to taking photos so we do have some small hard drive ranging from 500GB to 2TB laying around for backing up things. That's why I think, why not group them all so it can be accessible from one place?
First steps: Let it be a file storage
So at that time, I bought a HDD docking drive that supports USB 3.0, because one of those drive that laying around has already broken connector. I decide to buy a 2-bay docking station with USB 3.0 because Raspberry Pi 4 supporting it. It has two 2.5/3.5 SATA HDD bay for inserting around things. I am filling the HDD docking with a 2TB drive that I already has laying around but have a broken connector. For the second slot I'm putting a brand new Toshiba 3,5-inch 4TB drive for headroom of space. Then I also add a 4TB external drive that I have used for some time before. I connected it to a 1Gbps LAN directly to my router to maximize the speed and bandwidth.
It's a total of 10TB without any RAID array. I know it's bad, forgive me because I was on tight budget haha. It's a disaster waiting for the time to come because of no redundancy. If I have the budget, I would go with proper RAID-1 array minimum. But at that time, all I want is backing up things and I still have some external drive to do manual backup from this machine also.

From there, my curiosity keeps evolving. What can this machine can do other than "just" being a file storage? It's a Linux-based system so technically I could do anything I can do in a server, right?
Maximizing my Raspberry Pi use
When I was looking around for information about what projects are people running on their Raspberry Pi-s, I was adding some more software on my Raspberry Pi:
- DNS level router-wide AdBlocking with Pi-Hole.
- HomeAssistant running in docker for local Smart Home automation.
- MySQL server for storing database for my work projects.
- Sonarr for auto pulling weekly TV/anime shows.
- Radarr basically same like Sonarr but for movies.
- Plex server for self hosting streaming service alternatives.
Did you notice that many thing that we could serve in a single node of computer as small of that? Of course if you are going to serve it for many users, performance drops will be somewhat more noticeable. But for my needs as for a family of 4, and all of us rarely access it at same time it's much more than needed. And because of Raspberry Pi is an low power ARM-based computer, even at idle times it won't consume much power so electricity bills are not too much affected by the presence of it.
The goal of building a perfect homelab environment is set up once and do as little maintenance as possible when needed, that's what I've been doing for the past 3 years before I decide to think to take it to the next level.
Using my Unused Workstation PC as Homelab Server
After some time after my father passed away, my family decides to take some time to refresh ourself and go to our hometown. Because at that time, my younger sister hasn't finished her college yet and in her final projects phase. It was a time when I think that I can't carry out my workstation PC everywhere because it would be a hassle to do so. So I bought a pretty okay Asus ROG Flow X16 2022 with 8-core Ryzen 9 6900HS and RTX 3060 with 64GB of RAM. I am very impressed with the laptop overall and think this is an all in one laptop that I need. Even if the specs is not as good as my workstation PC, I am not feeling noticeable difference in day to day tasks from my perspective. I am planning to sell my PC after but because I am out of town for quite a long time, I haven't got a time to promote that on marketplace.

Then when I go out of town for around 8 month refreshing myself, I feel like I'm missing out something from my Homelab that I built before. I haven't tinkering around things for a while. I'm starting to rediscover that my workstation PC that long time I was not touching around after I am comfortable with my Laptop and leaving my town. That's when I starting to plan out what I would do in my PC. Researching about using Proxmox and the other thing I need to prepare to build my second addition to my home server.
Contemplation Phase
"Am I really need this? Am I really want this?"
Those question I always try to ask before trying to do something.
"Okay, I want it and I could use it for my learning needs. I could use it also to improve performance of my work, improving the kubernetes cluster and legacy system performance"
After some time for thinking, I am back home and tried to back up my PC contents and decided and installs Proxmox VE Community Edition to it. My server was quite okay, having 12-core Ryzen 9 5900X, 64GB of RAM and RTX 3070 8GB as the GPU. I was actually planning to set the GPU for a Windows VM so I could have own Steam Link server later. But I think because I rarely playing PC games, I just use my laptop for doing so. Leaving my pretty beefy GPU unused.
First Planned Setup
At first, my server configurations are like this:
- K3s Kubernetes Server: 4 CPU(s), 8GB Memory, 50GB LVM-Thin Disk.
- K3s Kubernetes Cluster 1: 4 CPU(s), 8GB Memory, 50GB LVM-Thin Disk.
- K3s Kubernetes Cluster 2: 4 CPU(s), 8GB Memory, 50GB LVM-Thin Disk.
- Harbor Server: 4 CPU(s), 8GB Memory, 100GB LVM-Thin Disk.
- File Server: 4 CPU(s), 8GB Memory, 50GB LVM-Thin Disk, 1TB LVM SSD assigned fully for it.
- Home Assistant Server: 2 CPU(s), 4GB Memory, 32GB LVM-Thin Disk.
I started migrating some of my old configurations from Raspberry Pi 4 to the File Server and Home Assistant Server Here. And tinkering around with the Kubernetes cluster for my work research to learn more about it and how to improve the legacy system behind it. But then, unexpected turn happens on my last workplace. A layoff wave we anticipated to come is coming to us before I have got a good use of the research that I do here. So at that time after my layoff announcement, I removed all the server containing K3S and Harbor for other thing first so I can sort out things that I want and need first. Maybe, later I will migrate my setup into a Kubernetes Cluster again when I am ready with the normal setup first.
Maxing out my File Server
Actually, I have thinking about this before I was coming back to home. I want the collection of photos that me and my late father taken to be stored neatly in one location. I am looking for the options available, after filtering out the options available here, I'm finally decided to take Immich for the job.
The reason why I chose Immich is because, even it's a relatively new project compared to the others it has the most GitHub stars and also has the familiar interface of Google Photos. It has included AI face grouping and CLIP based searching model feature also. Basically it's like having a private Google Photos in my home!
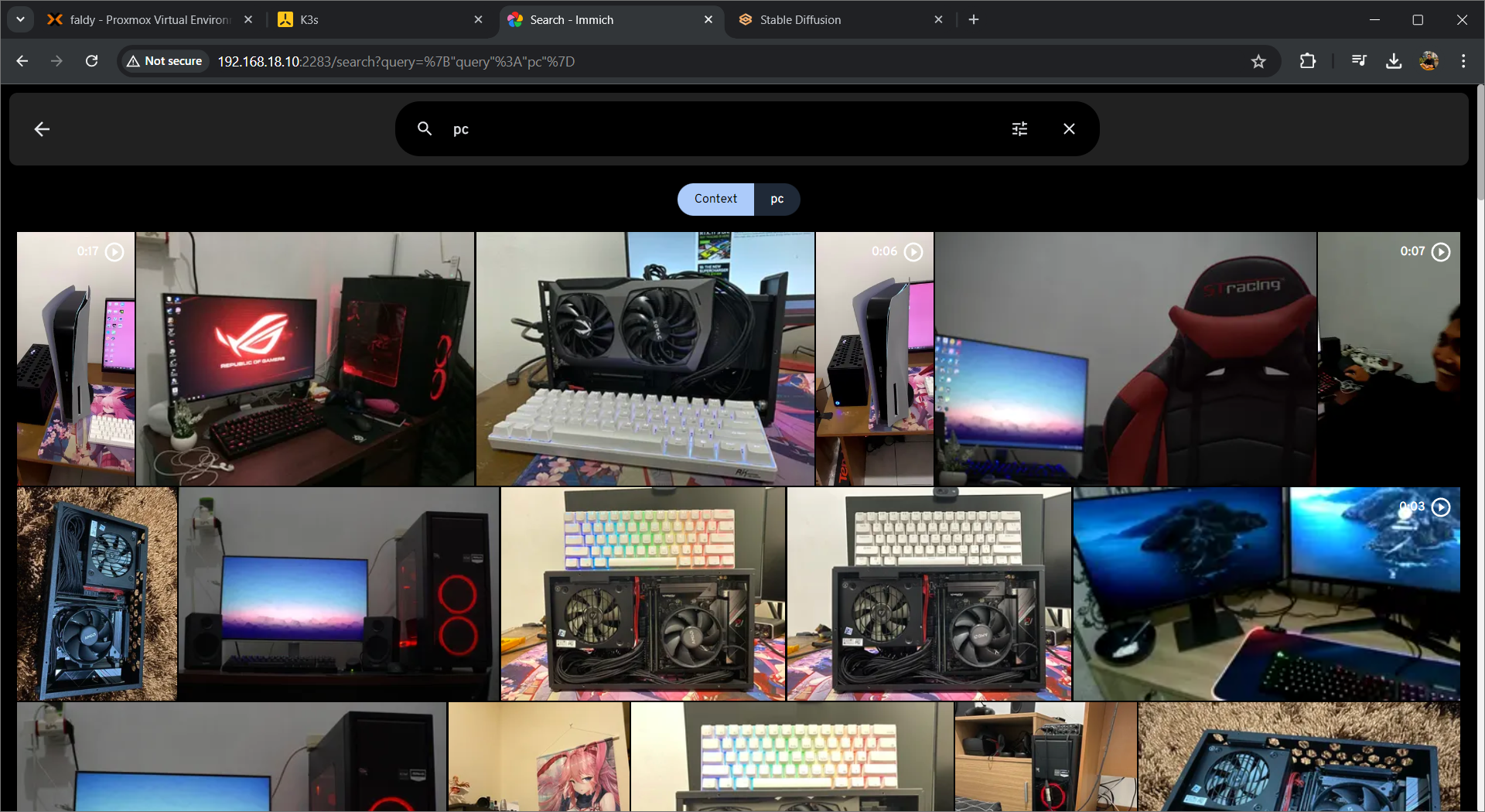
Here is the thing that I realize that I can maximize my GPU potential into my setup, AI/ML implementation. Immich benefits so much from additional CUDA core processing engine for the video transcoding, smart search, duplicate detection and facial recognition tasks. So I decide to passthrough the entire GPU to the File Server VM on Proxmox. It was fun and very rewarding when I do this, also because of my family can also backup in the same server, we could minimize the cloud subscribtion costs also.
Exposing to the internet
My blog which you was reading until now are hosted on my server on my home. I was long time not posting blog to the public and realized how important is Learn in Public: The fastest way to learn, which led me to think to start actively write again. The problem arise when I know my Biznet 150Mbps Home 1D Internet package worth Rp 375.000 per month (approx $23.05/mo) doesn't come out with a Public IP to expose with. If I want to expose my server applications directly to the internet, I need to upgrade to the 300Mbps Gamers 3D Internet package, which costs me almost 2 times more monthly at Rp 700.000 per month (approx $43.03/mo). I surely want as low cost as possible as for my need, 150Mbps is already good enough for me.
Cloud VPS to the rescue
I remember that I have a cloud VPS to store my NextChat instance for private ChatGPT-plus like experience without paying too much and some discord bot that I run. It's a fairly cheap droplet with 1 CPU/1 GB memory/25 GB SSD/ 1000 GB transfer at $6/mo which translates to around Rp 97.600 per month. The most important thing is, this has a Public IP that I need to expose my application. If I decide to go with this route, it's not bad right because I could save Rp 225.000 per month or approximately $13,83/mo. Not bad, right?
How exactly I do that is, I moved all the application that I run on the droplet to my Proxmox VM. Leaving just Nginx for the reverse proxy that we need to route to my home server later. Then I installed a OpenVPN server inside the DigitalOcean droplet. I created as many clients that I need so each of the VM will get a unique private IP that the droplet with a Public IP can expose the application with Nginx's Proxy Pass feature securely. I also added Cloudflare as a layer of security on the outer side.
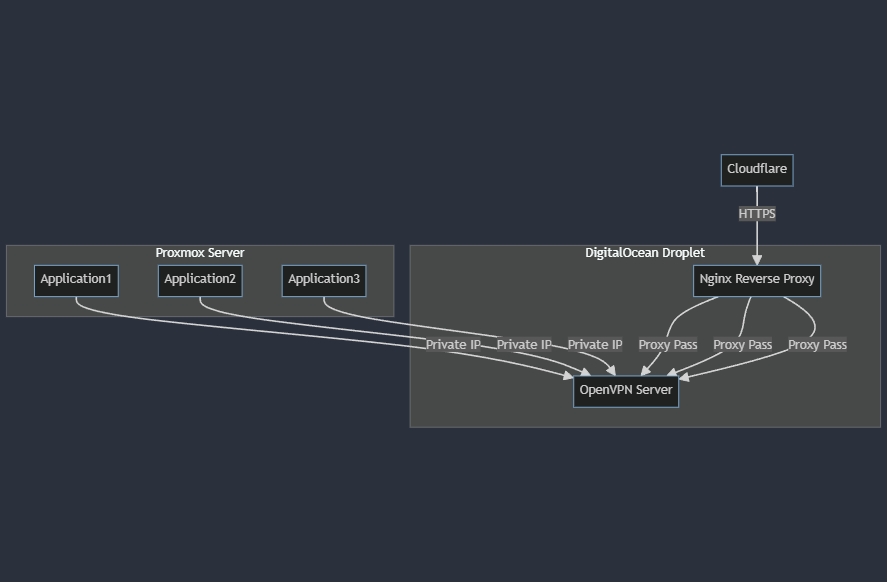
And there you go. With that kind of setup, my Ghost CMS-based blog that you can see now can be exposed directly to the internet in the help of VPN tunnel. I do a daily backup too to prevent something we don't want to happen.
Implementing more about applied AI stuffs
Large Language Model Chat UI
What I do next is to move my NextChat instance that I mentioned previously on. But I find that NextChat is a bit too basic for my needs. So I searched a lot of the other alternatives on the GitHub and found out about Lobe Chat.
When I first seeing and exploring Lobe Chat, I got intrigued by how it looks. It looks very clean and has a ton of features available, including Plugins, SSO Authentication and Local LLM support. Also being mobile friendly helps a lot for App-like experience PWA when used in smartphone. It also has a "Explore" menu to explore user-generated prompt library for our needs.
I started playing around with it's built in integration with the Local LLM ollama and installed some interesting local LLM. Including the integration with GitHub Copilot alternatives: Continue Plugin in JetBrains and VSCode. The benefits of running our LLM locally is, privacy issue that our data won't be consumed by other company. Not to mention we can get in control to fine tune the model ourself, like using uncensored version of LLM or tuned to be good on something specific.
Image Generation UI
I also add Stable Diffusion Web UI to my collection of apps. Being able to use Stable Diffusion in my server makes me can do image generation or training without a beefy system that I need to carry around everywhere. Even I can use stable diffusion from my phone outside of my local home network just by connecting to the VPN so it's not completely exposed to the internet.
Combining both of those above, I could create a personalized prompt using Lobe-Chat and make the personal assistant give me the detailed prompt for me. So it can optimize my workflow when generating the needed image. Of course not all the time I use local LLM, if I need something powerful I still need to use ChatGPT api or Claude API for getting their bigger model. Because my local machine is struggling to load a 27B model From Gemma2. Not to say Llama 3 with 70B of parameter 😄. I also do some SD training for text inversion training on my Proxmox Server, but I think that can be another story that I could post 😉.
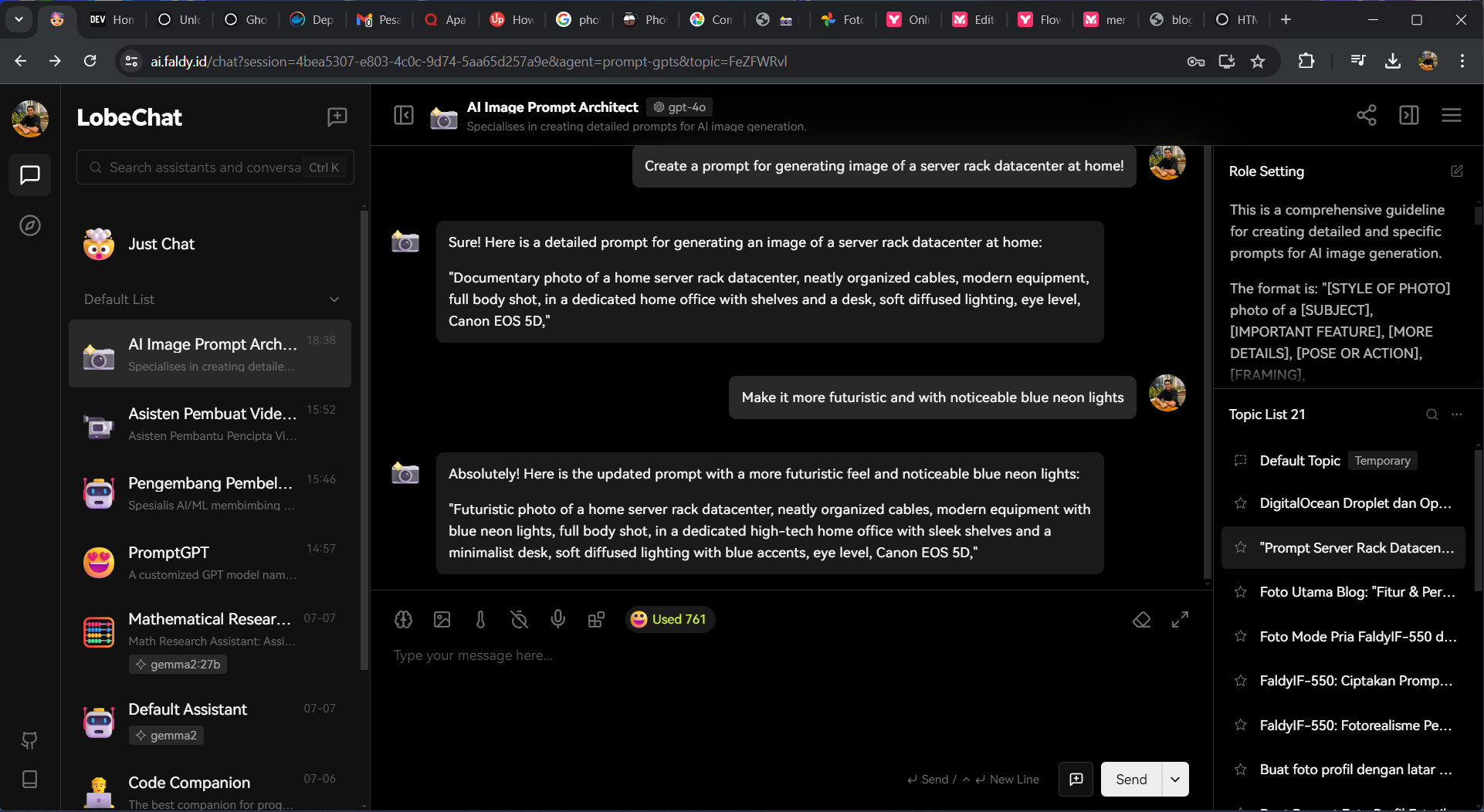
Wrapping Up
So in the end, my Proxmox Server is separated like this:
- MySQL Server: 2 CPU(s), 4GB Memory, 30GB LVM-Thin Disk.
- Ghost Server: 2CPU(s), 2GB Memory, 50GB LVM-Thin Disk.
- Docker Server 1: 2 CPU(s), 4GB Memory, 60GB LVM-Thin Disk.
- File Server: 14 CPU(s), 50GB Memory, 155GB LVM-Thin Disk. RTX 3070 6GB Passed through.
- Home Assistant Server: 2 CPU(s), 4GB Memory, 32GB LVM-Thin Disk.
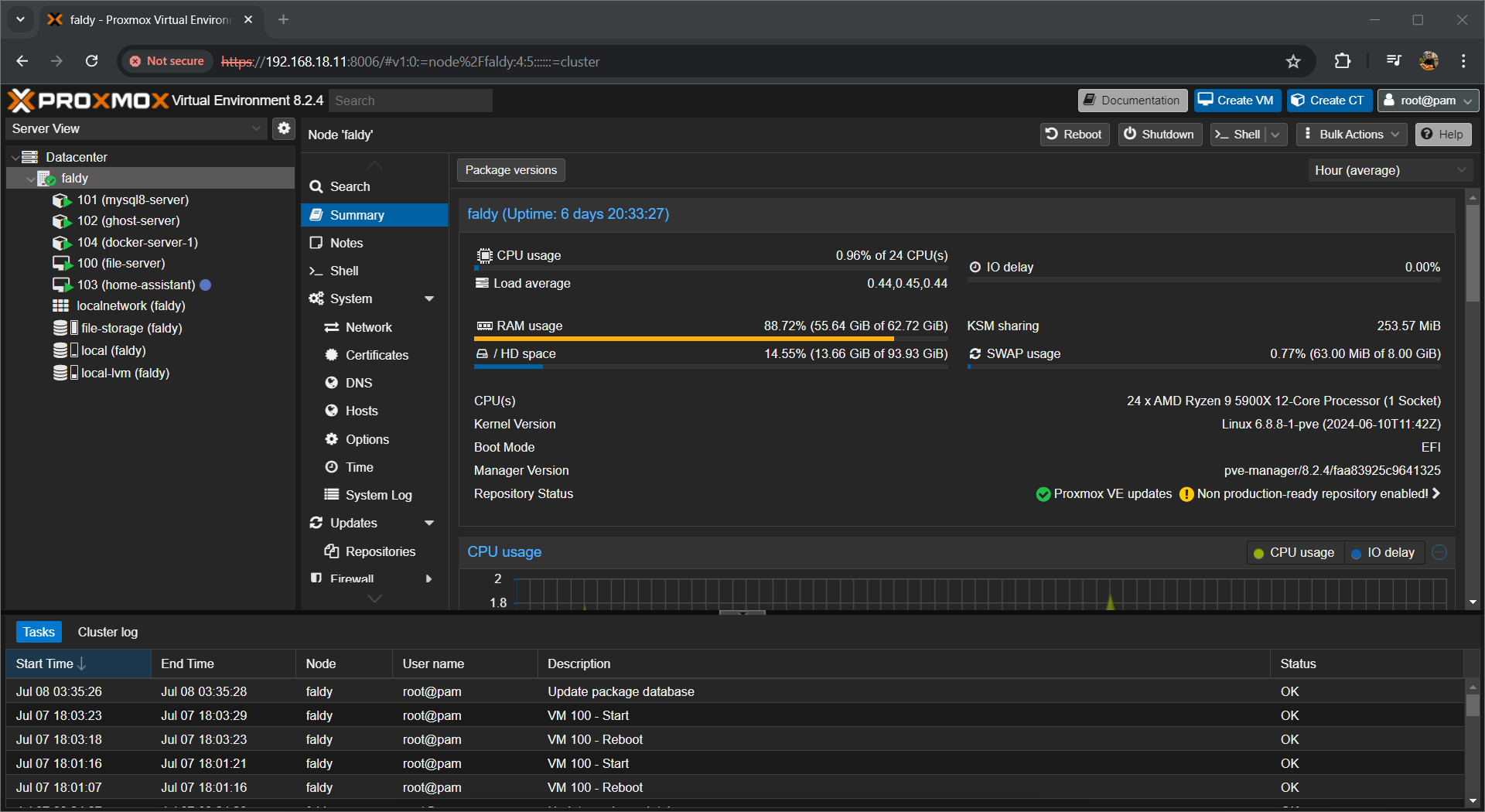
Yes, the file server seems like taking up too much of the resource. But it was me when I was curious to try some of bigger local LLM models that I need to load into the RAM and process it using the CPU. Also I still don't know how to split GPU resources to multiple server. If I do, maybe I'll do it and document it later in this blog but I don't think in the short time because what can even you split a 8GB VRAM again nowadays, loading a 8B LLM Locally would be a struggle after 😵.
Thank you for reading if you have been reading until now. See u again in my next story 😀